PostgreSQL - How to find duplicated rows in a table?
To show the duplicated records for a specific column:
SELECT * FROM table_name
WHERE (
SELECT count(*)
FROM table_name temp_table
WHERE table_name.col = temp_table.col) > 1;
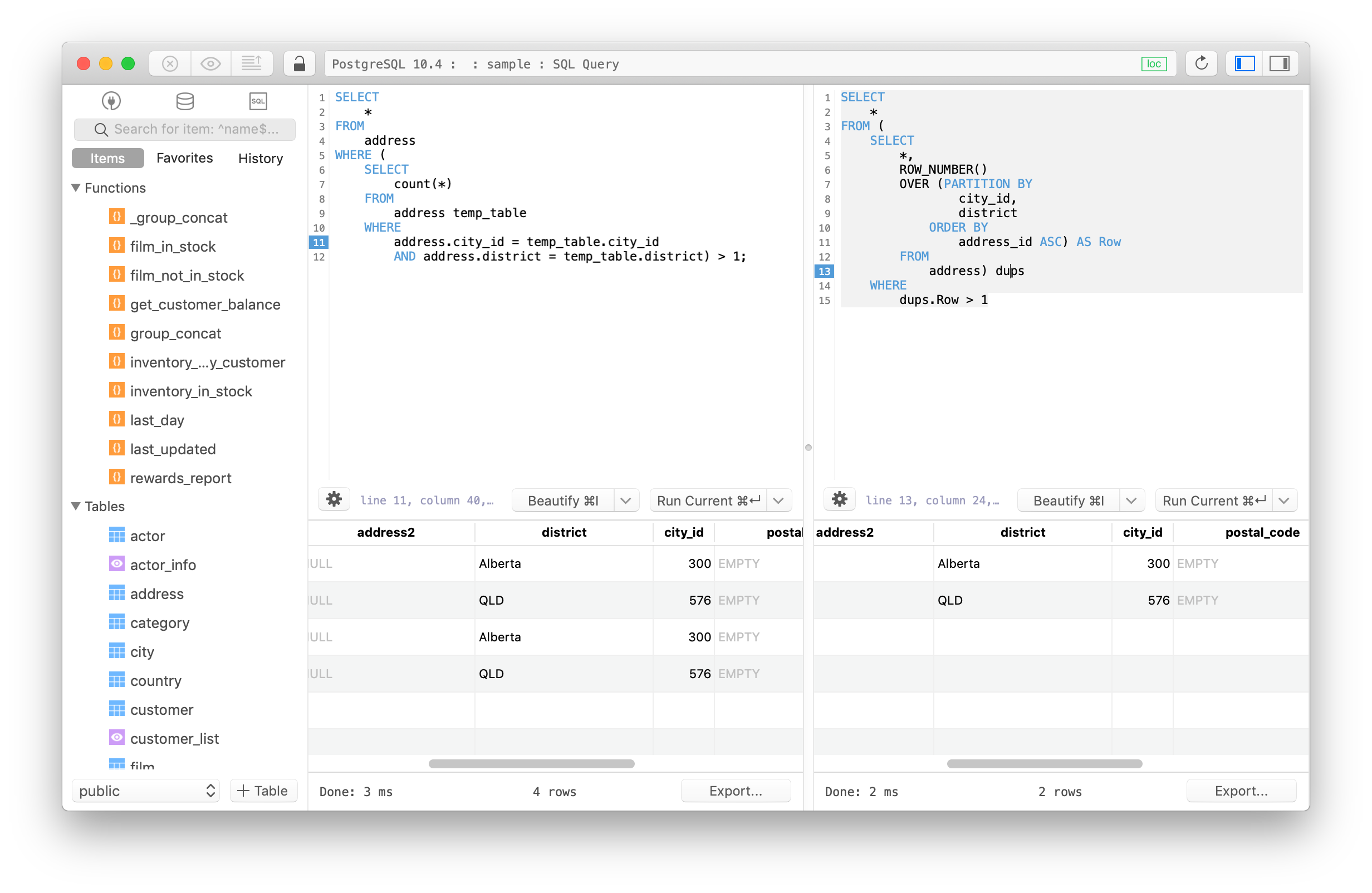
For example, list all the rows which have the duplicated city_id and district from the table address:
SELECT
*
FROM
address
WHERE (
SELECT
count(*)
FROM
address temp_table
WHERE
address.city_id = temp_table.city_id
AND address.district = temp_table.district) > 1;
Or for a faster speed, run this query:
SELECT
*
FROM (
SELECT
*,
ROW_NUMBER()
OVER (PARTITION BY
city_id,
district
ORDER BY
address_id ASC) AS Row
FROM
address) dups
WHERE
dups.Row > 1
Need a good GUI Tool for PostgreSQL? TablePlus is a modern, native tool with an elegant UI that allows you to simultaneously manage multiple databases such as MySQL, PostgreSQL, SQLite, Microsoft SQL Server and more.
Not on Mac? Download TablePlus for Windows.
On Linux? Download TablePlus for Linux
Need a quick edit on the go? Download TablePlus for iOS.